
Music generation with Recurrent Neural Networks
“Deep learning” describes the use of multilayer computational architectures, typically of Neural Networks, to capture a hierarchy of features embedded within the data. Some of these techniques have achieved super human performance in recent years on pattern recognition tasks. This post documents my experiments on implementing a multilayer recurrent neural network for learning musical patterns and generation. Code written in Python is hosted here.
Machine learning with Neural Networks
A typical Neural Network architecture consists of Neurons computing the weighted sum of it’s inputs and subsequently “squashing” the weighted sum with a non-linear function such as the hyperbolic tangent:
The squashing non-linearity helps the neural network to generlise. For the hyperbolic tangent function, the input can be thought of being gruoped into 3 categories, for large values of the weighted sum, no matter how large (in the practical sense), the tanh always evaluates to 1. Whereas for negative quantities, no matter how negative, the tanh function evaluates to -1. Outputs computed from weighted sum values near zero scales approximately linearly with the input. Overall, this means a large number of weighted sum result (and hence range of inputs ) are mapped to the same output value. And if the neuron is trained (with special weight configuration) to produce the same output for a group of related inputs, it possesses generalisation properties. The weights of each neuron adjusts the “preferred pattern” of the neuron. With the notation denoting the output neuron with it’s own weights - the entire layer of neurons can be specified by the parameters dictating how we scale the input for contributing to the output. Suppose a neuron is trained to “detect” (output firing) a large input at and a smaller input at , the corresponding weight will be large to amplify the effect of whereas the weight will be small to ensure small inputs does not contribute to the neuron firing (i.e. output = 1). The “preferred input pattern” for a neuron to fire is termed receptive field in neural science. In computing, the receptive field of an artificial neuron can be inferrred by visualising the weights of the trained neuron, often giving us a clue on what pattern this neuron is trained to detect. In the field of machine pattern recognition, raw data is often processed to extract useful “features” before a classifier. In most cases, the selection of features determines the performance of the system. The beauty of deep network architectures is the ability of a trained network to extract useful, hierahical features of the input data to improve classification accuracy. The features picked by the network is learnt with the training data through an numerical optimisation process. In some cases this can be done without an extensive understanding of the data and without having to decide on the best set of features to be used. Of course, a thorough understanding of the data and task at hand would help to train a better network by choosing an architecture that fits the data without too much redundancies or having to resort to computationally expensive fully connected nets. (e.g. localised receptive fields are used in ConvNets for image recognition).
In our experiment of training a network to produce music, the neuron outputs represent the probability of the respective notes being played (i.e. one neuron per note). Since more than one note can be played at the same time, we don’t normalise across the output neurons as in the case of classification. Instead, we use a sigmoid function as non-linearity so the outputs are always between 0 and 1. The purpose of training is to maximise the probability of the network producing a set of desired notes specified in the training set together with the input examples. For this we can use a simple squared error cost:
so when the squared error cost is small, the network is likely to produce the desired outputs correctly. To minimise the squared error cost we differentiate the cost function w.r.t the weights of the network and update weights at each training iteration according to:
After a number of weight updates and with an appropriately small update rate and meaningful inputs (not just random noise), the network would normally converge to a local minimum of the cost function. This is known as gradient descent, a common optimisation process for tuning model parameters to minimise a “cost”. The gradiet can be derived using the chain rule:
This way of evaluating the partial derivative of the cost function w.r.t the weights is known as back propagation. For a simple one layer feedforward network that simply computes the squashed weighted input sum, we can derive each of the partial derivative terms for weight updates for the squared error cost function:
thus the partial derivative (“error”) at each of the output neurons is computed by the difference in network computed probability (which is simply the signoid outputs) and the example probability (which is either 1 or 0) given the sqaured error as a cost function. The cost derivative w.r.t. the weight can be computed via the chain rule with . Using a simple single layer network with sigmoid output function as an example, is:
with denoting the derivative of the sigmoid. This partial derivative of the loss function can also be averaged over a number of training examples. i.e. evaluating
This process is known as mini batch training and can speed up convergence significantly.
An alternative cost function is to use the cross-entropy cost function, which measues the difference between a target distribution and the estimated distribution of a random variable :
Given that the probability of note to be played is simply the output of the neuron, and assuming the target probability provided by training data is still , we can compute the cross entropy loss at the output as:
In our music generation experiment, both cost functions were used for comparison.
Recurrent Networks and LSTM
The feedforward network described above takes the input layer and performs nonlinear transformation to produce the output. Recurrent Networks are Neural Networks that compute its outputs not just with the network input but also with the previous network states or outputs. This memorising capability allows recurrent networks to handle many interesting tasks including music generation as we’ve experimented here. A typical recurrent network computes the time varying output of the neuron according to:
The index here is used to step through the state in the same layer (assuming a single layer for now) and is the input of the layer at time . The input/outputs of a recurrent network thus come in the form of time series data. Note for each time step we use the same weights and bias scaling.
So we’ve seen how error can be back propagated towards the input layers and the derivative of the cost function with respect to the parameters evaluated on a feedforward network. For recurrent networks, this is slightly more complicated. At each time step , an output is computed by the network whereas for the purpose of training, an example output is also provided at each time step. Thus at each time step there is an error/cost function we can compute accoring to that we can use to calculate the parameter ( as weights and bias) updates by computing . The recurrent network utilises the computed states at time for feeding foward in time to evaluate the next states in time . Each time advancement stage thus involves the same parameters . In other words, each parameter contributes to the error at time through steps. The derivative of the parameter w.r.t. error at time can be derived according to the chain rule:
We can expand the expression by using the chain rule again:
This is the partial derivative of the cost function evaluated at time w.r.t parameter . The error signal at each time step contributes to the partial derivative of each parameter, thus practically we compute the “error” at the output and derive back propagation expressions for each weight parameter. This is known as Back Propagation Through Time(BPTT). We will futher illustrate this process in our three layer recurrent network.The total derivative of the total cost w.r.t parameter is given by the sum across all cost at times :
The gradient update for each parameter are carried out iteratively according to:
The chain rule facilitates computing the partial derivatives for weight updates through a product function of the partial derivative terms. For the simple single layer example, everytime we back propagate in time using the partial derivative we multiply an extra term in the following form towards the final gradient:
The derivative of the tanh function evaluates to regardless of it’s argument. For back propagation through time we can have the product of many terms. As a result, the product is likely to evaluate to a very small number, rendering the gradient contribution of errors at later time steps to approach zero. This means that the recurrent network will not have the correct updates for learning data with important temporal events separated by a long duration in time. This is known as the vanishing gradient problem in training recurrent networks as well as multilayer feedforward networks, where the error have to back propagate across a large number of layers following the chain rule and results in a large number of product terms.
The vanishing gradient is one of the main hurdles of training recurrent networks with gradient based methods as the gradient updates do not fully reflect the need to steer the cost function in the correct direction towards a local minima. This is deeply rooted into the network architecture of using activation function such as the hyperbolic tangents or sigmoids. A number of remidies have been proposed to tackle the vanishing gradient updates, one of them being the Long-Short Term Memory (LSTM) architecture, where a linear memory unit is used without a nonlinear activation function. The error propagation from the memory unit itself at a later time thus do not suffer from a vanishing gradient. The short commings of using linear units in a neural network is compensated by memory “gate” units controlling whether the linear (memory) unit is updated according to the input (input gate) and whether the output of a linear unit is propagated to the layer output (output gate), as well as controlling whether the memory unit should retain its old value (forget gate). So the “neuron” unit in a LSTM is different from those of the traditional RNNs. The general LSTM architecuture specifies gate sharing with the same gate controlling a number of linear units. A graphical description of a single “neuron” cell of the LSTM is shown below. The memory variable is feedback to itself without nonlinearity, hence the gradient do not “vanish” over time. The gate and output unit computation involves either a logistic function or tanh nonlinearity and in principle still suffers from a vanishing gradient when the network is trained by gradient based methods. Having said that, LSTMs have shown extreme effectiveness in picking up temporal events separated by a long time lag in a large number of practical scenarios.
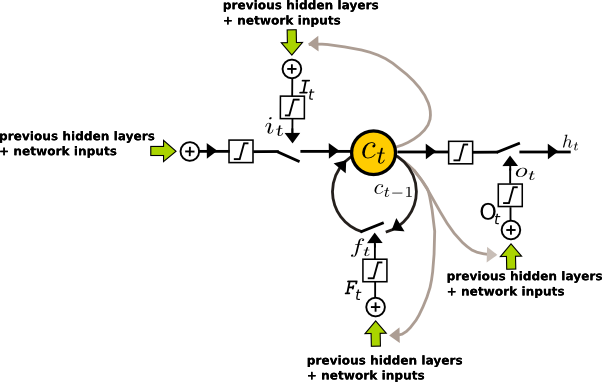
We have dropped the layer indication in the diagram such that the cell described can belong to any layer of a deep network. denotes the output of a hidden unit in the multilayer architecture. The overall output of the deep network is computed as the weighted sum of a number of these hidden units.
Multilayer LSTM
In a multilayer LSTM, connecting the output of each layer to the overall network output directly aids gradient back propagation for the gate parameters. The overall network architecture is illustrated below:
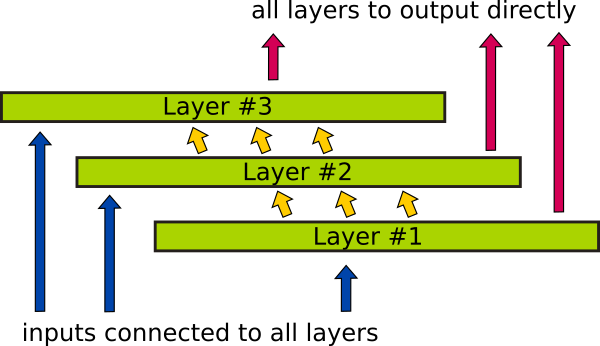
Using column vectors for the layer variables and weight matrixes while denoting element-wise multiplication by , the forward pass in time and space of the three layer LSTM are described by:
Where is the network’s input vector at time and denotes the output of each layer (sometimes called “hidden states”) at time . and symbols denote network weight matrixes and bias vectors respectively. , , and are elementwise sigmoid functions applied to a column vector. The symbols , , and respectively denotes the outputs at time of the layer’s input, forget, and output gates. For the convenience of calculating the cost gradients w.r.t the weights, we also define symbols , , and as the respective weighted sumed inputs before nonlinearity is applied at the input, forget, and output gates. This is also illustrated in the LSTM cell figure above. denotes the state of the memory unit at time and in layer . The corresponding linear weighted sum is defined as . The network output is computed by weighted sum of the output of all three layers, again we define a symbol as the output signal before the elementwise sigmoid is applied:
The three layers in our LSTM implementation are cascaded with output of one layer connected to the input of the next. However, since the overall network output receives contribution from all three layers directly, the three layers can be thought of a cascade and parallel hybrid.
Back propagation in time and space in LSTM
Following the chain rule, the backward error equations are derived for each layers:
From the error vectors, the weight gradients can be computed as the following outer products. All vectors are column vectors with row vector transposes:
The weights and biases can then be updated by the above gradients (summed across time and averaged acrossed training examples) scaled by a small training rate.
Music generation with LSTM - Practical issues
The three layer LSTM is implemented using the Python/Theano (0.7) framework. Gradients were calculated using the equations above without relying on the symbolic differentiation of Theano. The main reason is that symbolic differentation took too long to compile with my setup (or may be there were bugs in the code…). The manually derived error terms also relied on assumptions such as is independent of while calculating from . Incorporating these assumptions in Theano’s symbolic differentiation is likely to speed things up but requires experimenting with “constant settings” in the gradient routine. On the other hand, implementing the equations directly using Theano tensor operators still results in good training speed even with my limited hardware setup (mobile 2.3GHz i5, no GPU). A rolling average of the gradient were used for each update (RMSprop). The three layer network in the experiment have 120 hidden units for each layer.
Both squared error and cross entropy cost functions are implemented in the code for experimentation. The network is initialised with all weights set to zero and a small gaussian noise to break the symmetry. All bias were set such that the network starts in the middle of all nonlinearities. E.g. for the logistic function, biases are initialised to with a small gaussian noise whereas for tanh activated neurons, biases are initialised around zero with small amount of noise added. All weights and bias update rates are set to 0.01. The network is trained with the Nottingham database of folk tunes using the link from an official Theano example exploring a different RNN-RBM architecture for music generation. The network is trained by supplying midi files as mini-batches and the lenght of each tune in a mini-batch is set by the user. With this, shorter tunes are extended by repeats and longer tunes are truncated. Typically the network converges to a local minimum after few hundreds of gradient updates with update rates of 0.001. Further training without regularisation in the cost function results in over training of the network.
To generate music using a trained network, we first run through a few (20-100) notes from an example piece as input to the network and subsequently connect the network output as input at the next time step. Notes with probability are ignored. The piano roll of a typical generated piece (mp3) with the hpps tunes in the Notthingham database with the cross entropy error cost function (300 gradient updates and 50 example points leading the generation) is shown below:
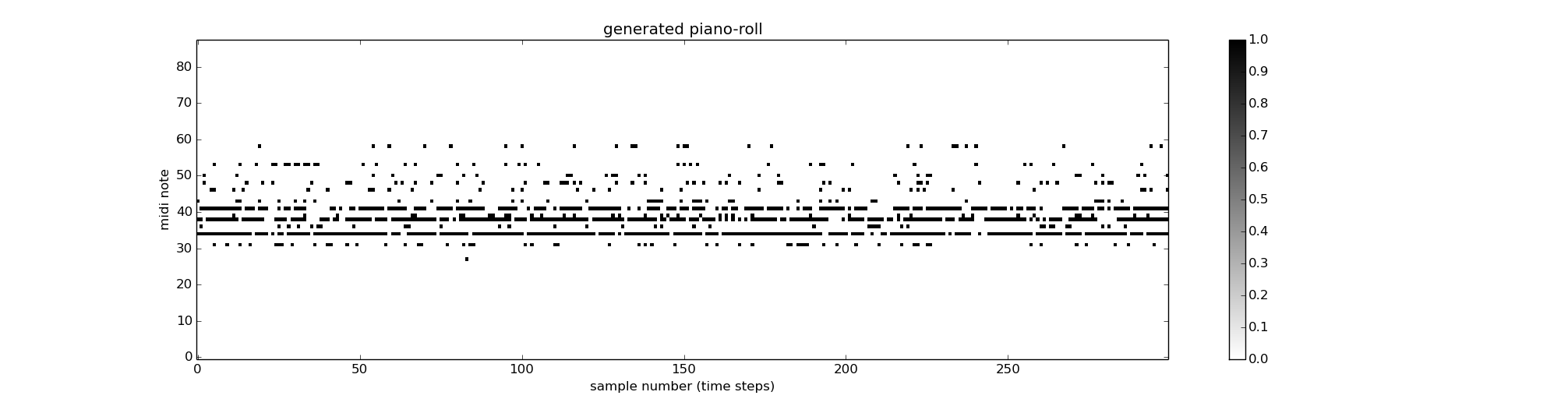
The original training data for generating the above piece consists of a large number of consecutive notes between midi notes #30 and #44. Hence the probability of generating between these notes are generally high. The typical probability of note production of the network is shown below:
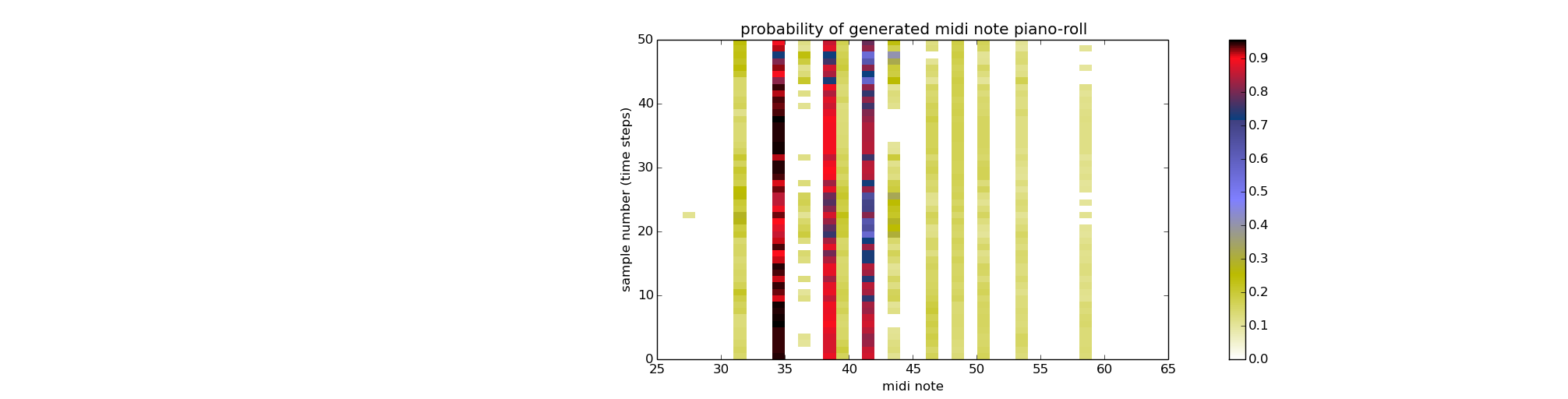
There is a clear pattern in the probability evolution with only a subset of the possible notes having a higher probability of being produced by the network. We find that with more training, the network exhibits over-training and the generation probability of each note becomes constant and resembles the average appearance probability of each note in the training set. It’s been suggested in literature that randomising the weights slightly between each gradient updates helps to prevent over-training and allow the network to pick up more subtle patterns. I am yet to experiment with this. The following shows a typical piano-roll (mp3) genearted by a network trained with the sqaure error cost function, following the same 300 gradient updates and 50 examples points leading the generation:
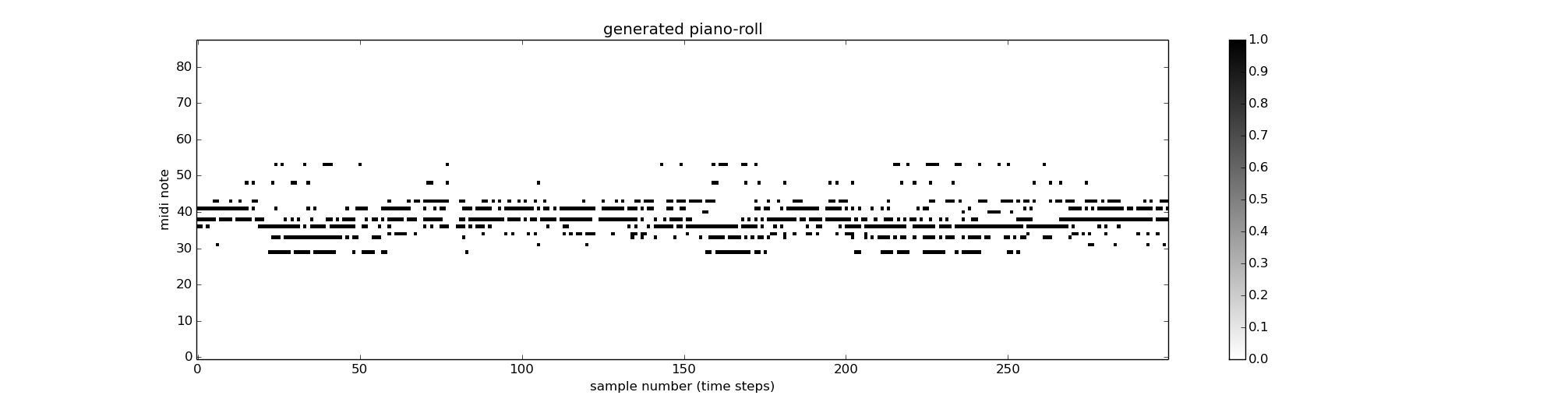
with corresponding probabilities for the first 50 time steps:
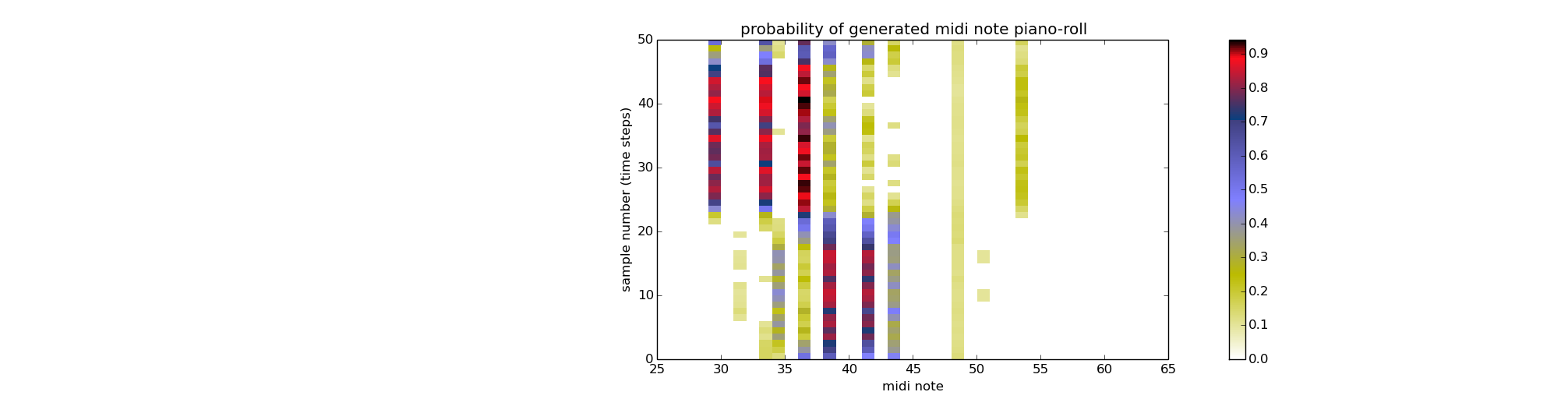
For more info on how to use the code seee the README on the main repository page.
References
Papers, thesis, and videos that helped me along (almost essential!) with the experiment:
-
This work is largely inspired by the official Theano example on music generation, which uses RBM and a classical RNN architecture. Also useful are the recommended Python Midi library in the link.
-
Great lecture by Andrew Ng on back propagation.
-
The Deep LSTM architecture with direct output/input connections to each layer is taken from Alex Graves “Generating Sequenes with Recurrent Neural Networks” Neural and Evolutionary Computing
-
Chapter 2 of Alex Graves’ thesis “Supervised Sequence Labelling with Recurrent Neural Networks” presented the derivation of the back prop equations for more general cases.
-
Geoffrey Hinton’s video lecture on mini batch training, Rprop, and RMSprop.